![]()
![]()
- What is MatrixOne
- Get Started in 60 Seconds
- Tutorials & Demos
- Installation & Deployment
- Architecture
- Python SDK
- Citing MatrixOne
- Contributing
- License
MatrixOne is the industry's first database to bring Git-style version control to data, combined with MySQL compatibility, AI-native capabilities, and cloud-native architecture.
At its core, MatrixOne is a HTAP (Hybrid Transactional/Analytical Processing) database with a hyper-converged HSTAP engine that seamlessly handles transactional (OLTP), analytical (OLAP), full-text search, and vector search workloads in a single unified system—no data movement, no ETL, no compromises.
Just as Git revolutionized code management, MatrixOne brings Git-style workflows to data management. The design behind this capability is detailed in the arXiv paper Version Control System for Data with MatrixOne, and in practice it lets you manage your database like code:
- 📸 Instant Snapshots - Zero-copy snapshots in milliseconds, no storage explosion
- ⏰ Time Travel - Query data as it existed at any point in history
- 🔀 Branch & Merge - Test migrations and transformations in isolated branches
- ↩️ Instant Rollback - Restore to any previous state without full backups
- 🔍 Complete Audit Trail - Track every data change with immutable history
Why it matters: Data mistakes are expensive. Git for Data gives you the safety net and flexibility developers have enjoyed with Git—now for your most critical asset: your data.
|
🗄️ MySQL-Compatible Drop-in replacement for MySQL. Use existing tools, ORMs, and applications without code changes. Seamless migration path. |
🤖 AI-Native Built-in vector search (IVF/HNSW) and full-text search. Build RAG apps and semantic search directly—no external vector databases needed. |
☁️ Cloud-Native Storage-compute separation. Deploy anywhere. Elastic scaling. Kubernetes-native. Zero-downtime operations. |
The typical modern data stack:
🗄️ MySQL for transactions → 📊 ClickHouse for analytics → 🔍 Elasticsearch for search → 🤖 Pinecone for AI
The problem: 4 databases · Multiple ETL jobs · Hours of data lag · Sync nightmares
MatrixOne replaces all of them:
🎯 One database with native OLTP, OLAP, full-text search, and vector search. Real-time. ACID compliant. No ETL.

docker run -d -p 6001:6001 --name matrixone matrixorigin/matrixone:latestmysql -h127.0.0.1 -P6001 -p111 -uroot -e "create database demo"Install Python SDK:
pip install matrixone-python-sdkVector search:
from matrixone import Client
from matrixone.orm import declarative_base
from sqlalchemy import Column, Integer, String, Text
from matrixone.sqlalchemy_ext import create_vector_column
# Create client and connect
client = Client()
client.connect(database='demo')
# Define model using MatrixOne ORM
Base = declarative_base()
class Article(Base):
__tablename__ = 'articles'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(200), nullable=False)
content = Column(Text, nullable=False)
embedding = create_vector_column(8, "f32")
# Create table using client API
client.create_table(Article)
# Insert some data using client API
articles = [
{'title': 'Machine Learning Guide',
'content': 'Comprehensive machine learning tutorial...',
'embedding': [0.1, 0.2, 0.3, 0.15, 0.25, 0.35, 0.12, 0.22]},
{'title': 'Python Programming',
'content': 'Learn Python programming basics',
'embedding': [0.2, 0.3, 0.4, 0.25, 0.35, 0.45, 0.22, 0.32]},
]
client.batch_insert(Article, articles)
client.vector_ops.create_ivf(
Article,
name='idx_embedding',
column='embedding',
lists=100,
op_type='vector_l2_ops'
)
query_vector = [0.2, 0.3, 0.4, 0.25, 0.35, 0.45, 0.22, 0.32]
results = client.query(
Article.title,
Article.content,
Article.embedding.l2_distance(query_vector).label("distance"),
).filter(Article.embedding.l2_distance(query_vector) < 0.1).execute()
for row in results.rows:
print(f"Title: {row[0]}, Content: {row[1][:50]}...")
# Cleanup
client.drop_table(Article) # Use client API
client.disconnect()Fulltext Search:
...
from matrixone.sqlalchemy_ext import boolean_match
# Create fulltext index using SDK
client.fulltext_index.create(
Article,name='ftidx_content',columns=['title', 'content']
)
# Boolean search with must/should operators
results = client.query(
Article.title,
Article.content,
boolean_match('title', 'content')
.must('machine')
.must('learning')
.must_not('basics')
).execute()
# Results is a ResultSet object
for row in results.rows:
print(f"Title: {row[0]}, Content: {row[1][:50]}...")
...That's it! 🎉 You're now running a production-ready database with Git-like snapshots, vector search, and full ACID compliance.
💡 Want more control? Check out the Installation & Deployment section below for production-grade installation options.
Ready to dive deeper? Explore our comprehensive collection of hands-on tutorials and real-world demos:
| Tutorial | Language/Framework | Description |
|---|---|---|
| Java CRUD Demo | Java | Java application development |
| SpringBoot and JPA CRUD Demo | Java | SpringBoot with Hibernate/JPA |
| PyMySQL CRUD Demo | Python | Basic database operations with Python |
| SQLAlchemy CRUD Demo | Python | Python with SQLAlchemy ORM |
| Django CRUD Demo | Python | Django web framework |
| Golang CRUD Demo | Go | Go application development |
| Gorm CRUD Demo | Go | Go with Gorm ORM |
| C# CRUD Demo | C# | .NET application development |
| TypeScript CRUD Demo | TypeScript | TypeScript application development |
| Tutorial | Use Case | Related MatrixOne Features |
|---|---|---|
| Pinecone-Compatible Vector Search | AI & Search | vector search, Pinecone-compatible API |
| IVF Index Health Monitoring | AI & Search | vector search, IVF index |
| HNSW Vector Index | AI & Search | vector search, HNSW index |
| Fulltext Natural Search | AI & Search | fulltext search, natural language |
| Fulltext Boolean Search | AI & Search | fulltext search, boolean operators |
| Fulltext JSON Search | AI & Search | fulltext search, JSON data |
| Hybrid Search | AI & Search | hybrid search, vector + fulltext + SQL |
| RAG Application Demo | AI & Search | RAG, vector search, fulltext search |
| Picture(Text)-to-Picture Search | AI & Search | multimodal search, image similarity |
| Dify Integration Demo | AI & Search | AI platform integration |
| HTAP Application Demo | Performance | HTAP, real-time analytics |
| Instant Clone for Multi-Team Development | Performance | instant clone, Git for Data |
| Safe Production Upgrade with Instant Rollback | Performance | snapshot, rollback, Git for Data |
MatrixOne supports multiple installation methods. Choose the one that best fits your needs:
Run a complete distributed cluster locally with multiple CN nodes, load balancing, and easy configuration management.
# Quick start
make dev-build && make dev-up
# Connect via proxy (load balanced)
mysql -h 127.0.0.1 -P 6001 -u root -p111
# Configure specific service (interactive editor)
make dev-edit-cn1 # Edit CN1 config
make dev-restart-cn1 # Restart only CN1 (fast!)📖 Complete Development Guide → - Comprehensive guide covering standalone setup, multi-CN clusters, monitoring, metrics, configuration, and all make dev-* commands
One-command deployment and lifecycle management with the official mo_ctl tool. Handles installation, upgrades, backups, and health monitoring automatically.
📖 Complete mo_ctl Installation Guide →
Build MatrixOne from source for development, customization, or contributing. Requires Go 1.22, GCC/Clang, Git, and Make.
📖 Complete Build from Source Guide →
Docker standalone, Kubernetes, binary packages, and more deployment options.
MatrixOne's architecture is as below:
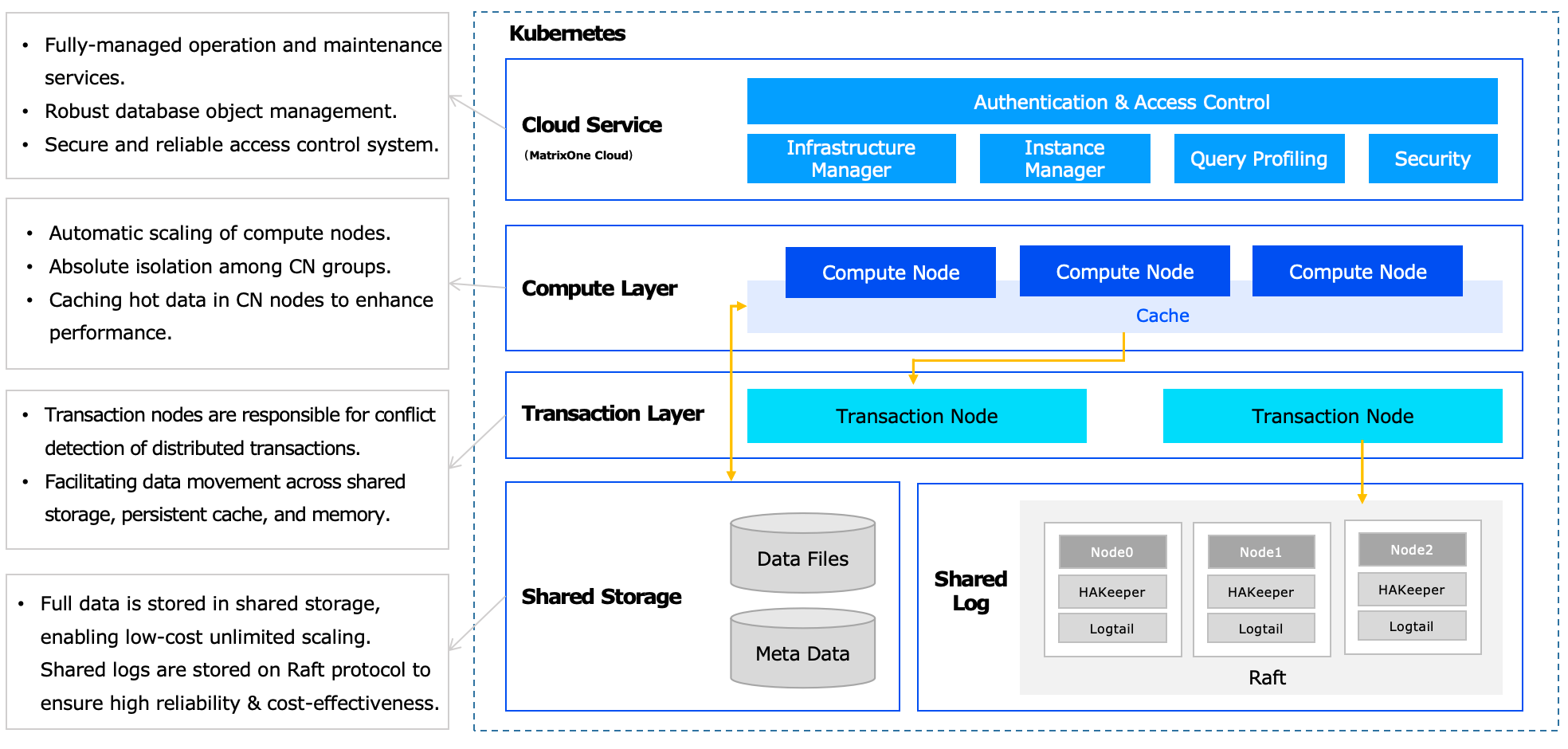
For more details, you can checkout MatrixOne Architecture Design.
MatrixOne provides a comprehensive Python SDK for database operations, vector search, fulltext search, and advanced features like snapshots, PITR, and account management.
Key Features: High-performance async/await support, vector similarity search with IVF/HNSW indexing, fulltext search, metadata analysis, and complete type safety.
📖 Python SDK README - Full features, installation, and usage guide
📦 Installation: pip install matrixone-python-sdk
If you use MatrixOne in academic work or refer to its Git for Data design, please cite:
@misc{gou2026versioncontrolsystemdata,
title={Version Control System for Data with MatrixOne},
author={Gou, Hongshen and Tian, Feng and Wang, Long and Deng, Nan and Xu, Peng},
year={2026},
eprint={2604.03927},
archivePrefix={arXiv},
primaryClass={cs.DB},
doi={10.48550/arXiv.2604.03927},
url={https://arxiv.org/abs/2604.03927}
}Contributions to MatrixOne are welcome from everyone.
See Contribution Guide for details on submitting patches and the contribution workflow.








































































































MatrixOne is licensed under the Apache License, Version 2.0.