Open Chat is a basic transformer architecture library that is still in development.
First, add the repository as a submodule.
git submodule add https://github.com/Bean91/Open-Chat.git
Then, include the file in your code.
#include "/include/model.hpp"
For extended documentation, please view the docs (still in development)
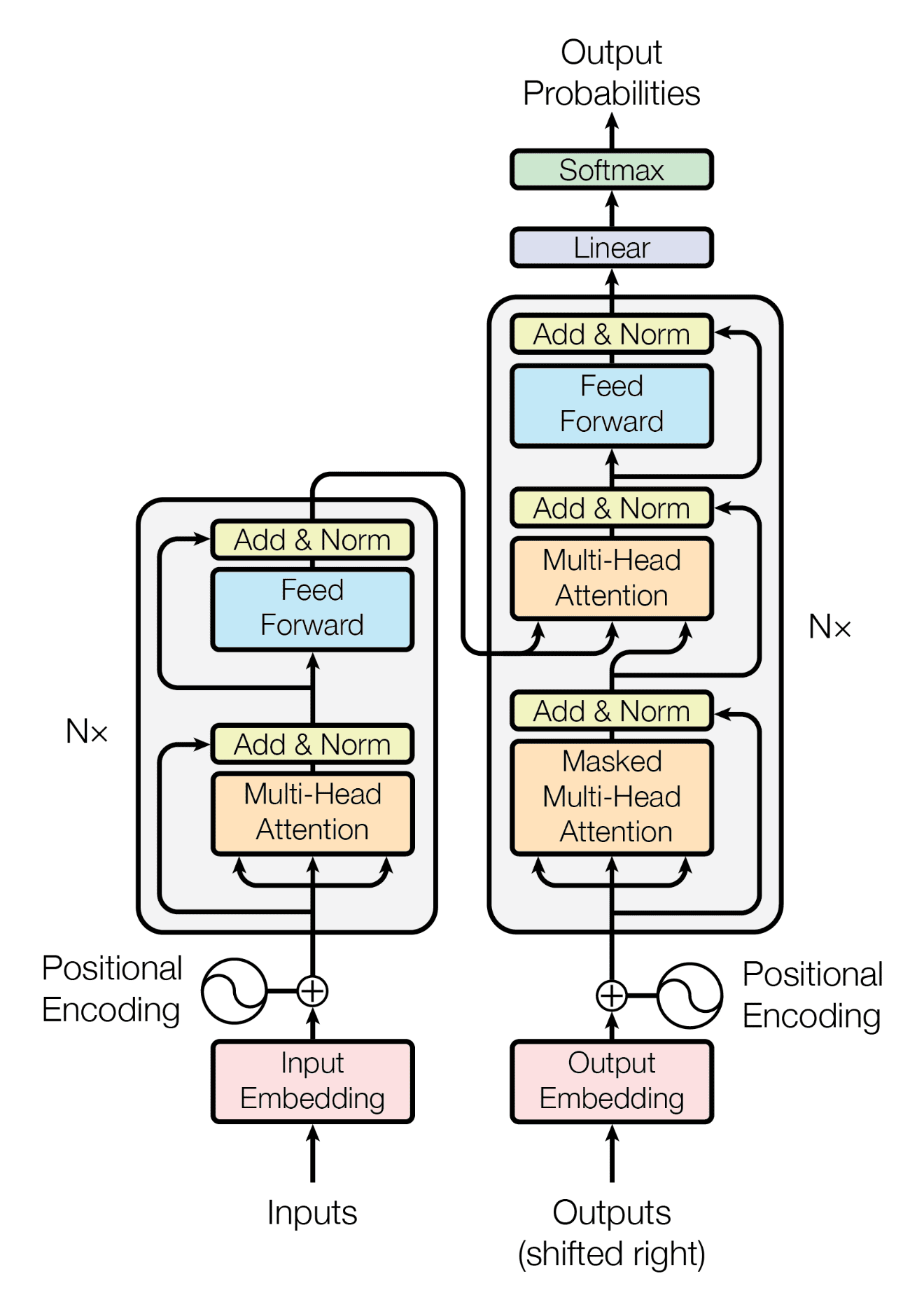
Inputted text follow the architecture outlined in the image above. Each step will be gone into depth. This architecture is how many modern chatbots function.
In essence, tokenization turns a string of characters into a vector (or list of values) of integer values. A tokenizer has a set library of key (integer ID) value (token) pairs. So, if a value is recognized, it replaces that value with the key. For example, if you wanted to tokenize Hello, World!, one token could be 124: "Hel", another 347: "lo, ", 439: "Worl", and 110: "d!". This would replace the original string with a vector (list of values) [124, 347, 439, 110] for use in the next steps.
An embedding is a long vector of floats (decimals) for a certain token. The point of turning the tokens into embeddings is to represent the meaning for the transformer to understand. Embeddings are stored in a large table, so the token 98: "Hi" would be looked up (in the table), and would return a large list. For a basic embedding table with 5 dimensions, token 98 could be converted to [0.3, -0.8, 0.9, 0.2, -0.1]. This represents meaning, as similar words (hi vs hello), in a very high-dimension space, will have a very similar direction. Obviously, in larger models, the embedding dimensions will be much larger (think 1024 or 2048) to give more meaning to each token.
The math equations represent a value added to each vector embedding. These values represent the position of each dimension for the model. This enables the model to understand word order.
Each embedding is stacked into a large matrix denoted by
The output from this formula gives the new
The
The formula for each layer is shown above. This gets passed through every layer.
The transformed
When a text request is made, first the request gets tokenized into a vector of IDs. Next, for each ID, they get embedded, stacking each embedding to create the
This was made as a school semester project (v1 at least). Also, this is still in development. It is not complete.
If you would like to contribute, please look at the GitHub Repository